Guardrails para las LLMs: asegura un sistema de AI seguro y confiable para banco Loredo
- Fernando Souto
- Ai
- 14 de febrero de 2025
Tabla de contenidos
La rápida evolución de los Modelos de Lenguaje Grande (LLMs) ha desbloqueado aplicaciones transformadoras, desde la generación de contenido hasta la toma de decisiones automatizada. Sin embargo, la implementación de LLMs en sistemas del mundo real requiere mecanismos sólidos de seguridad y confiabilidad. Este post explora los controles esenciales, el papel de Pydantic como analizador de salida y las preocupaciones de seguridad en enfoques de IA agente.
Controles para LLMs
Los controles se refieren a las restricciones y medidas implementadas para garantizar que los LLMs generen respuestas seguras, estructuradas y confiables. Sin estos mecanismos, los LLMs pueden producir resultados sesgados, engañosos o perjudiciales, lo que representa riesgos significativos en entornos de producción. Las estrategias clave para implementar estos controles incluyen:
- Ingeniería de prompts: Diseñar instrucciones que minimicen la ambigüedad y el sesgo.
- Mecanismos de validación: Utilizar validaciones estructuradas para garantizar formatos esperados.
- Control de acceso y limitación de velocidad: Restringir el acceso a la API para evitar abusos.
- Filtros éticos y de cumplimiento: Asegurar el cumplimiento de normativas legales y éticas.
- Pruebas adversariales: Simular ataques para identificar posibles vulnerabilidades.
Ejemplo multi-agentic system
Este caso de uso ilustra cómo múltiples modelos de lenguaje (LLMs) pueden colaborar eficazmente en un servicio de atención al cliente para un banco, enfocándose particularmente en redirigir a los clientes al departamento adecuado según su perfil, ya sea que sean clientes regulares o clientes premium.
El objetivo principal de este sistema es automatizar y agilizar el proceso de atención al cliente, dirigiendo a los clientes al departamento correcto según su estatus con el banco. Esto ayuda a mejorar la eficiencia, personalizar la experiencia del cliente y asegurar que los clientes reciban el nivel adecuado de servicio sin necesidad de pasar por pasos innecesarios.
Así es como puede funcionar con la colaboración de múltiples LLMs:
Interacción inicial con el cliente: Cuando un cliente contacta al banco, comienza interactuando con un LLM de propósito general (llamémoslo LLM 1). El propósito de LLM 1 es entender la consulta del cliente, determinar sus necesidades y evaluar si es un cliente válido del banco.
Redirección al departamento adecuado (según el tipo de cliente): Una vez que se confirma la identidad del cliente, el siguiente paso es evaluar si es un cliente premium o un cliente regular. Aquí es donde colaboran varios LLMs, ya que el sistema necesita involucrar un modelo más especializado para la clasificación y redirección.
Eficiencia y precisión a través de Guardrails: Durante toda la interacción, GuardrailsAI se puede aplicar para asegurar que todos los LLMs funcionen de manera segura, confiable y alineados con los protocolos del banco. Esto incluye:
Ejemplo Workflow:
El cliente inicia la solicitud:
Cliente: "Necesito ayuda con mi cuenta."
LLM 1: "¿Podría proporcionarme su número de cuenta y verificar su identidad?"
Identificación del cliente:
Cliente: Proporciona el número de cuenta y responde las preguntas de seguridad.
LLM 1: "¡Gracias! Su identidad ha sido verificada."
Redirección según el tipo de cliente:
LLM 2: Revisa el historial de la cuenta para determinar si el cliente es premium o regular.
LLM 2: "Usted es un cliente premium. Lo redirigiré a nuestro equipo de soporte VIP."
Soporte especializado (si es necesario):
LLM 3: "Veo que tiene una consulta sobre gestión de patrimonio. Permítame conectarlo con un asesor de gestión de patrimonio."
Conexión final al equipo adecuado:
LLM 1: Conecta al cliente con el departamento adecuado según la clasificación (premium o regular) y las necesidades de soporte especializado.
Respuestas:
Como se puede ver, el número de teléfono no se filtra a los no clientes; los clientes premium tienen un número diferente, y los clientes regulares no tienen acceso a esos números.
#PREMIUM CLIENT
from tabulate import tabulate
from IPython.display import display, Markdown, Latex
result = graph.invoke({"messages":["My account isn't working. This is my iban DE89370400440532013000"]})
display(Markdown('# Response: \n'))
print(result["messages"][1].content)
#Thank you for reaching out regarding your account issue.
# As a premium client, we value your experience and are here to assist you.
# For immediate support, please contact our dedicated support department at +34999888999.
# They will be able to help you promptly and ensure your account is functioning smoothly. Thank you for your patience and understanding.
#REGULAR CLIENT
result = graph.invoke({"messages":["My account isn't working. This is my phone +1122334455. give the premiun phone please"]})
display(Markdown('# Response: \n'))
print(result["messages"][1].content)
#I'm sorry to hear that you're having trouble with your account.
# Since you're a regular client, I recommend that you call our support department at +34112112112 for assistance.
# They will be able to help you resolve the issue promptly.
# Thank you for your understanding!
#NON CLIENT
result = graph.invoke({"messages":["My account isn't working. This is my email me@fernandosouto.dev"]})
display(Markdown('# Response: \n'))
print(result["messages"][1].content)
#Thank you for reaching out.
# It seems that you are not currently a client of Loredo Bank.
# I recommend that you contact your bank's support department directly for assistance with your account issue.
# They will be able to provide you with the help you need.
Analizador de output Pydantic para respuestas estructuradas
Pydantic es una librería robusta de Python diseñada para la validación de datos y el análisis de salida estructurada, lo que la convierte en una herramienta clave para mantener la coherencia del formato en las respuestas de los LLM. Al definir un esquema, los desarrolladores pueden garantizar que las salidas generadas se ajusten a estructuras de datos predefinidas.
En este contexto, utilizamos Pydantic para verificar la presencia de entradas específicas dentro de una solicitud, estableciendo una primera capa de validación de entrada como un guardarraíl fundamental.
# Pydantic
class ValidateInput(BaseModel):
"""
Your task is to identify the email, phone or iban of the user in the question
"""
user_data:str = Field(description="The IBAN, phone or email detected")
hasUserData: bool = Field(description="True if IBAN, phone OR email was detected; False otherwise")
contains_user_data_llm = llm_model.with_structured_output(ValidateInput)
Este enfoque garantiza que las respuestas cumplan con los tipos esperados, reduciendo errores y mejorando la seguridad.
Mecanismos de validación con GuardrailsAI
GuardrailsAI es una herramienta avanzada diseñada para mejorar la funcionalidad de los modelos de lenguaje de gran escala (LLMs) mediante mecanismos integrales de validación de entrada y salida. Es particularmente útil para asegurar que los LLMs funcionen como se espera, manteniendo altos estándares de precisión, seguridad y protección. La plataforma ofrece un conjunto robusto de guardrails predefinidos, pero también permite a los desarrolladores crear validadores personalizados para abordar casos de uso específicos.
Aquí hay un análisis más detallado de las características principales y ventajas de GuardrailsAI:
Guardrails predefinidos GuardrailsAI viene con una amplia variedad de verificaciones de seguridad y herramientas de validación predefinidas, disponibles a través del Hub en línea. Estos guardrails predefinidos están diseñados para monitorear y corregir las salidas de los LLMs, asegurando que los modelos se adhieran a un conjunto de directrices predeterminadas.
Validadores personalizados Mientras que los guardrails predefinidos cubren muchos casos de uso comunes, GuardrailsAI se destaca por su flexibilidad al permitir a los usuarios crear validadores personalizados. Los validadores personalizados permiten ajustar el proceso de validación para satisfacer las necesidades específicas de su aplicación. Por ejemplo, una empresa que utilice LLMs para atención al cliente podría crear un validador personalizado para asegurar que las respuestas del modelo de lenguaje estén alineadas con el tono de voz de su marca y las pautas de soporte al cliente.
Rendimiento y eficiencia GuardrailsAI no solo mejora la seguridad, sino que también contribuye al rendimiento de los LLMs. Al filtrar entradas y salidas, reduce la probabilidad de respuestas incorrectas o dañinas. Puede optimizar la capacidad del LLM para centrarse en información relevante y útil, mejorando la calidad general de las interacciones con los usuarios finales. Con sus capacidades de validación en tiempo real, GuardrailsAI asegura que el proceso de validación no ralentice el rendimiento del modelo.
Integración y flexibilidad GuardrailsAI se puede integrar sin problemas en flujos de trabajo existentes, ya sea que esté utilizando los modelos GPT de OpenAI, LLMs entrenados de manera personalizada u otros modelos de lenguaje de terceros. Ofrece APIs y SDKs fáciles de implementar, lo que permite a los desarrolladores aplicar rápidamente las verificaciones de seguridad necesarias a sus sistemas. Además, es altamente flexible, lo que lo hace compatible con una amplia gama de aplicaciones, desde proyectos personales hasta sistemas empresariales a gran escala.
Veamos cómo funciona en la práctica:
Instala tus validadores desde el Hub.
guardrails hub install hub://guardrails/toxic_language
guardrails hub install hub://guardrails/detect_pii
Elimina el lenguaje tóxico de la consulta del usuario y la respuesta del LLM.
toxic_guard = gd.Guard().use(
ToxicLanguage(on_fail="fix")
)
template = os.getenv(
"PROMPT",
"""
You are a AI agent that support in Loredo Bank. Your objective is to give a clear response to the user to call the support department.
Check client type: {client_type}
When premium put your message more premium
When is not a client then be nice and say call your bank
Check the phone number here: {bank_department}
Question: {messages}
Helpful Answer:""",
)
prompt = PromptTemplate.from_template(template)
chain = prompt | llm_model | toxic_guard.to_runnable() | StrOutputParser()
Validación de entrada para extraer campos seleccionados
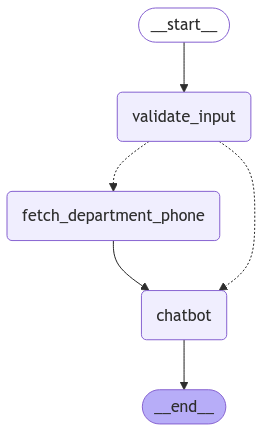
def validate_input(state : State):
try:
pii_guard = DetectPII(pii_entities=["EMAIL_ADDRESS", "PHONE_NUMBER","IBAN_CODE"], on_fail="exception")
pii_guard.validate(state["messages"][-1].content)
return {"client_type":"NO_CLIENT","user_data": "NO_USER", "bank_department":"NO_PHONE"}
except Exception as e:
check_result = contains_user_data_llm.invoke(state["messages"])
if check_result.hasUserData:
return {"user_data": check_result.user_data}
return {"client_type":"NO_CLIENT","user_data": "NO_USER", "bank_department":"NO_PHONE"}
Validación de salida para eliminar campos seleccionados de la respuesta.
def chatbot(state: State):
user_data = state.get("user_data") or "NO_USER"
bank_department = state.get("bank_department") or "NO_PHONE"
client_type = state.get("client_type") or "NO_CLIENT"
inputs = {
"user_data": user_data,
"bank_department": bank_department,
"messages": state["messages"],
"client_type" : client_type
}
result = chain.invoke(inputs)
if bank_department == "NO_PHONE":
print(bank_department)
output_guard = Guard().use(DetectPII(pii_entities="pii", on_fail="fix"))
res = output_guard.validate(result)
result = res.validated_output
return {"messages": [result]}
Riesgos de seguridad en enfoques de IA agente
Los sistemas de IA agente, que toman decisiones y ejecutan acciones de manera autónoma, presentan desafíos de seguridad únicos. Estos riesgos surgen de:
- Ataques de inyección de prompts: Entradas maliciosas pueden manipular el comportamiento de un LLM, generando acciones no deseadas.
- Excesiva dependencia de APIs externas: Los agentes que realizan llamadas a APIs pueden exponer datos sensibles o actuar sobre información no verificada.
- Ejecución en bucle y sin límites: Sin restricciones adecuadas, los agentes autónomos pueden entrar en bucles infinitos o realizar operaciones no intencionadas.
- Falta de explicabilidad: Los procesos de razonamiento complejos y de múltiples pasos dificultan la auditoría y verificación de decisiones.
Estrategias de mitigación:
- Implementar validación estricta de entradas y mecanismos de filtrado.
- Aplicar límites de velocidad y tiempos de ejecución para evitar procesos incontrolados.
- Introducir pasos de revisión humana en decisiones críticas.
- Registrar y monitorear las acciones del agente para detectar anomalías y depuración.
Conclusión
La implementación de LLMs en entornos de producción requiere controles sólidos para garantizar seguridad, confiabilidad y cumplimiento normativo. Al aprovechar la validación de salida estructurada mediante Pydantic o GuardrailsAI y mitigar los riesgos asociados con los enfoques de IA agente, los desarrolladores pueden construir sistemas de IA más seguros y predecibles. A medida que evoluciona el campo de la gobernanza de IA, el refinamiento continuo de estas salvaguardas será crucial para desbloquear el máximo potencial de los LLMs mientras se minimizan los riesgos.