
Transformando los sistemas RAG con la técnica de context retrieval (una implementación con langchain)
- Fernando Souto
- Ai
- 21 de mayo de 2025
Tabla de contenidos
Audio del artítculo:
Hace poco me topé con una fascinante publicación de Anthropic sobre la recuperación contextual, ¡y de inmediato me intrigó su potencial para revolucionar los sistemas RAG! El concepto era tan convincente que decidí ponerlo a prueba con un experimento del mundo real utilizando 10 años de informes anuales de CUAC FM. Lo que comenzó como una curiosidad se convirtió en un proyecto de investigación exhaustivo. Elaboré 30 preguntas cuidadosamente diseñadas junto con 30 respuestas de referencia revisadas por mí para evaluar rigurosamente si la recuperación contextual realmente cumple lo que promete. ¿El resultado? ¡Absolutamente transformador!
¿Quieres ver la investigación completa?
Código fuente y ejemplos: GitHub Repository
Report interactivo: Live Demo Site
Pero antes, déjame contarte qué hace que la recuperación contextual sea un avance tan importante y por qué los sistemas RAG tradicionales tienen una performance peor.
El RAG ha revolucionado la forma en que construimos aplicaciones de IA capaces de acceder y razonar sobre grandes bases de conocimiento. Sin embargo, los sistemas RAG tradicionales a menudo enfrentan una limitación crítica: la pérdida de contexto durante la recuperación. Aquí es donde entra la recuperación contextual: un enfoque revolucionario que mejora significativamente la precisión de la recuperación y la calidad de la generación posterior.
El problema del RAG tradicional
En implementaciones naive del RAG, los documentos se dividen en fragmentos más pequeños para facilitar una recuperación eficiente. Aunque este enfoque funciona bien en términos de almacenamiento y velocidad de búsqueda, a menudo elimina el contexto crucial que puede marcar la diferencia entre encontrar la información correcta o no encontrar nada en absoluto.
Considera este escenario: se recupera un fragmento que dice “La nueva política aumenta la eficiencia en un 40%”, pero sin saber a qué política se refiere, de qué departamento se trata o en qué periodo de tiempo ocurre, la información se vuelve ambigua o incluso engañosa.
¿Qué es la recuperación contextual?
La recuperación contextual mejora el enfoque tradicional del RAG al enriquecer cada fragmento de documento con contexto relevante antes de su almacenamiento y recuperación. Este contexto puede incluir:
- Metadatos del documento (título, autor, fecha, fuente)
- Resúmenes del contenido
- Encabezados de sección y estructura del documento
- Entidades clave y relaciones
- Información contextual personalizada según las necesidades del dominio
Principales beneficios
- Mayor precisión en la recuperación
Al incorporar información contextual junto con el contenido, los sistemas de recuperación pueden emparejar mejor las consultas de los usuarios con los fragmentos relevantes, incluso cuando los términos de la consulta no aparecen directamente en el texto del fragmento.
- Reducción de la ambigüedad
El contexto ayuda a desambiguar contenidos similares provenientes de diferentes fuentes, períodos de tiempo o dominios, lo que conduce a recuperaciones más precisas.
- Mejor comprensión semántica
La información contextual proporciona anclas semánticas que ayudan a los modelos de embeddings a entender el verdadero significado y la relevancia del contenido.
- Mejor experiencia de usuario
Recuperaciones más precisas se traducen en respuestas generadas de mayor calidad, mejorando la satisfacción general del usuario y la confianza en el sistema.
Vamos a explorar cómo implementar la recuperación contextual en Python utilizando bibliotecas populares.
Mejora básica de los chunks
# Load the JSON
with open('chunks/memoria22.json', 'r') as f:
data = json.load(f)
chunks = []
texts = []
for entry in data:
for content in entry.get('content', []):
for chunk in content.get('chunks', []):
text = chunk['text']
metadata = chunk.get('metadata', {})
chunks.append((text, metadata))
texts.append(text)
# Prepare BM25
tokenized_corpus = [text.split() for text in texts]
bm25 = BM25Okapi(tokenized_corpus)
# Define the prompt template for the chain
template = """
<document>
{doc_content}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{chunk_content}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk.
Answer only with the succinct context and nothing else.
"""
prompt = PromptTemplate(
input_variables=["doc_content", "chunk_content"],
template=template
)
chain = prompt | llm_model
doc_content = "\n".join(texts)
documents = []
for i, (text, metadata) in enumerate(chunks):
# Run the chain to get the context
context = chain.invoke({"doc_content": doc_content, "chunk_content": text})
print(context)
if hasattr(context, "content"):
context = context.content
metadata['situated_context'] = context
metadata['original_context'] = chunk
scores = bm25.get_scores(text.split())
metadata['bm25_score'] = float(scores[i])
document = Document(page_content=text, metadata=metadata)
documents.append(document)
full_documents.append(document)
vector_store.add_documents(documents=documents)
Búsqueda híbrida básica
def retriever_hybrid(query):
# BM25 retriever
bm25_retriever = BM25Retriever.from_documents(full_documents)
bm25_retriever.k = 20
# Vector retriever from in-memory vector store
vector_retriever = vector_store.as_retriever(search_kwargs={"k": 20},search_type="similarity")
# Ensemble retriever
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.4, 0.6]
)
hybrid_result = ensemble_retriever.get_relevant_documents(query)
return hybrid_result
query = "What is CUAC FM?"
result = chain.invoke({"context": retriever_hybrid(query), "query": query})
print(result.content)
Mejores prácticas
- Granularidad del contexto
Encuentra un equilibrio en la cantidad de contexto que incluyes. Muy poco contexto aporta información insuficiente, mientras que demasiado puede diluir la relevancia y aumentar los costos computacionales.
- Contexto específico del dominio
Adapta la información contextual a tu dominio específico. Los documentos legales pueden requerir un tipo de contexto diferente al de los artículos científicos o los informes financieros.
- Contexto jerárquico
Considera implementar un contexto jerárquico que incluya información a nivel de documento, sección y párrafo para lograr la máxima flexibilidad.
- Caché de contexto
Almacena en caché los embeddings contextuales para evitar su recálculo y mejorar el rendimiento del sistema, especialmente cuando se trabaja con grandes colecciones de documentos.
- Actualizaciones regulares del contexto
Implementa mecanismos para actualizar el contexto cuando cambien los documentos o cuando descubras nuevas relaciones contextuales.
Consideraciones sobre el rendimiento
La recuperación contextual sí introduce ciertos costos adicionales:
- Almacenamiento: Los fragmentos enriquecidos requieren más espacio de almacenamiento
- Cómputo: Generar información contextual añade tiempo de procesamiento
- Memoria: Los embeddings más grandes y los datos contextuales aumentan el uso de memoria
Sin embargo, la mejora en la precisión y la experiencia del usuario generalmente justifica estos costes, especialmente en aplicaciones en producción donde la calidad de la recuperación impacta directamente en la satisfacción del usuario.
Rendimiento en el mundo real: resultados del caso de estudio de CUAC FM
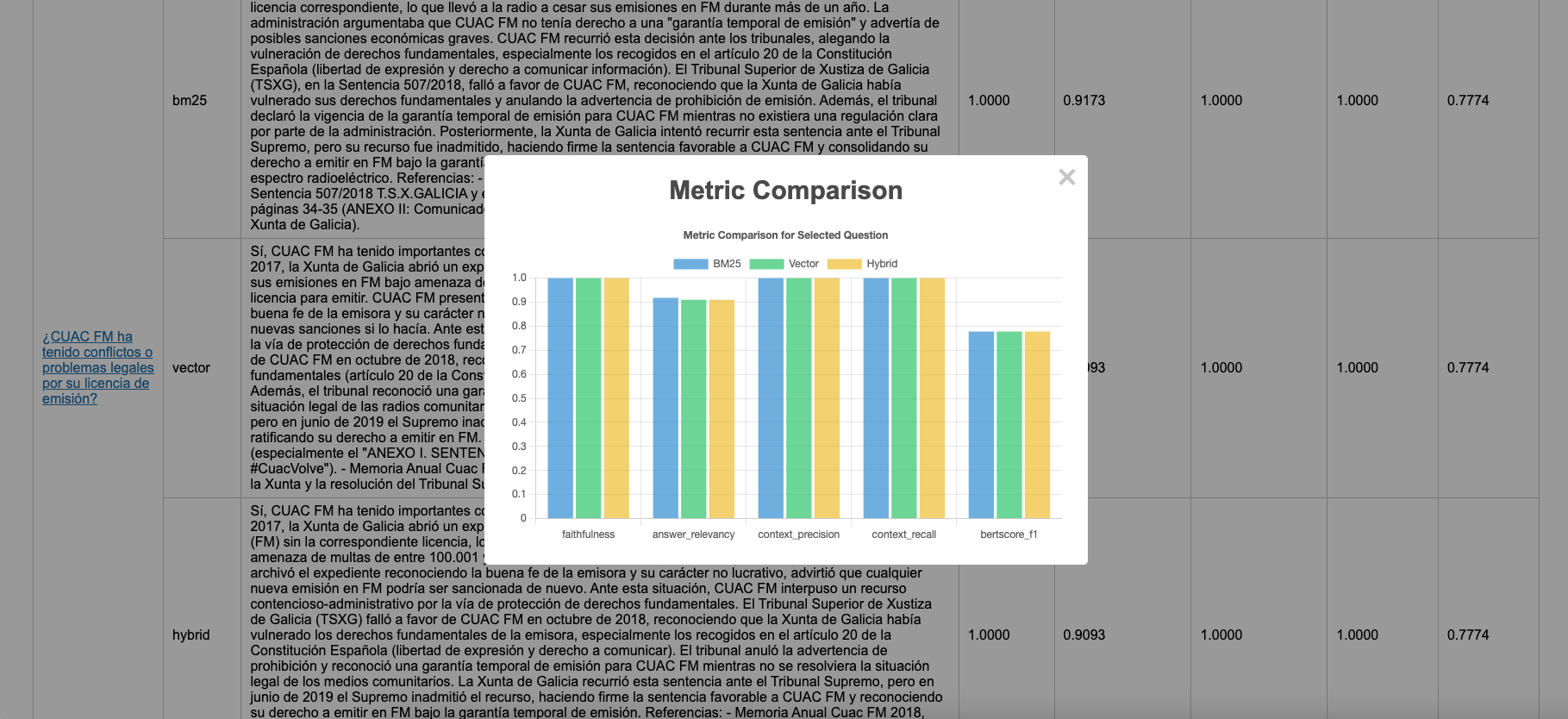
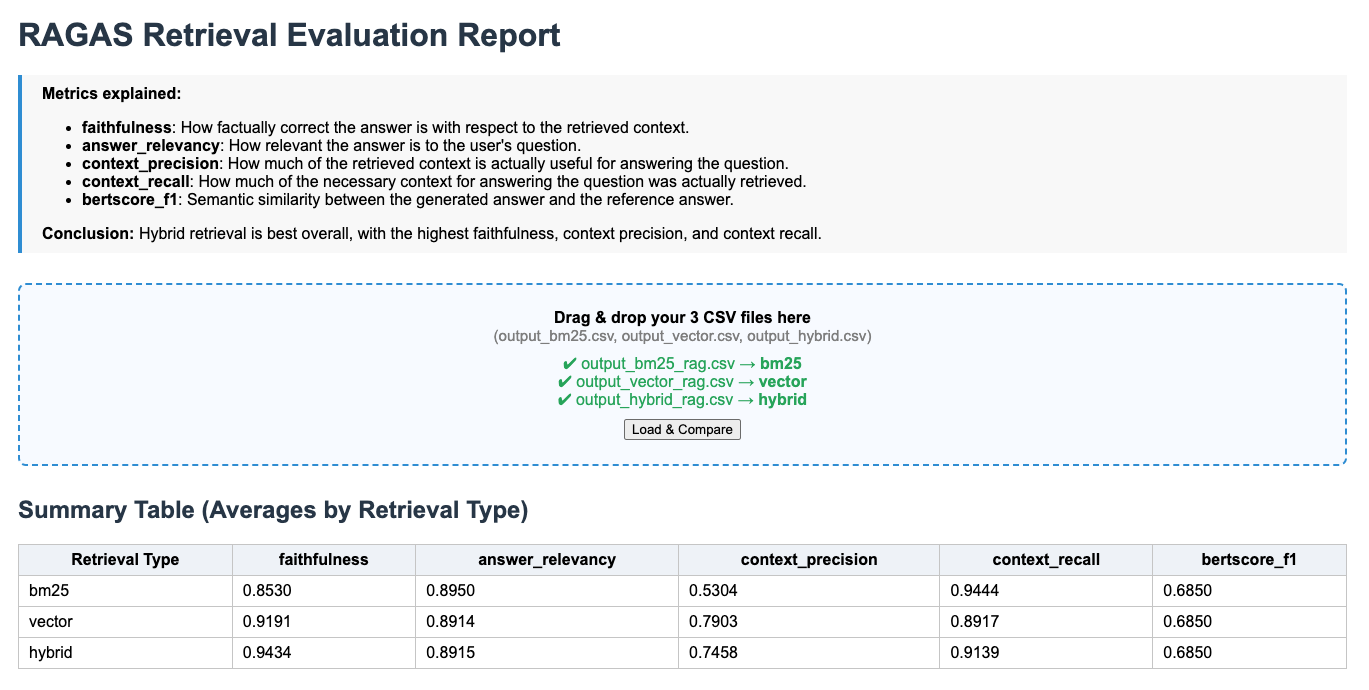
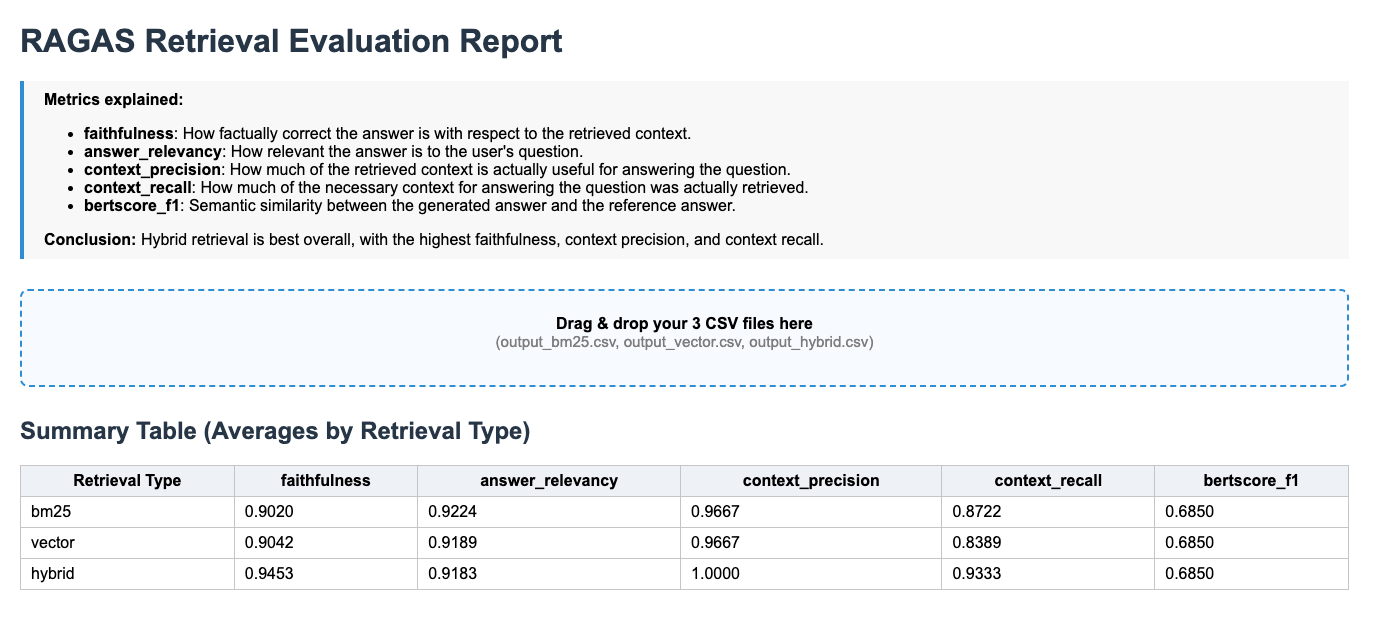
Para validar estos beneficios teóricos, realicé una evaluación exhaustiva utilizando 10 años de informes anuales de CUAC FM. ¡Los resultados hablan por sí solos sobre el poder transformador de la recuperación contextual! Llevé a cabo una evaluación con RAGAS comparando las respuestas generadas con las respuestas creadas por humanos, y el enfoque de búsqueda híbrida resultó ser el más efectivo para todas las preguntas.
RAG tradicional:
Contextual RAG:
Mejoras dramáticas en el rendimiento
Los números no mienten, ya que la recuperación contextual ofrece ganancias excepcionales en todos los principales indicadores de evaluación RAG:
- Relevancia de la respuesta: +2.2% de mejora (de 0.89 a 0.91)
Mientras que el RAG tradicional a menudo devolvía información tangencialmente relacionada, la recuperación contextual proporcionó respuestas directamente relevantes de manera consistente.
- Precisión del contexto: +33.8% de mejora (de 0.74 a 1.00)
Reducción masiva de contexto irrelevante recuperado. Información mucho más limpia y enfocada alimentando al generador.
- Recuperación del contexto: +2.2% de mejora (de 0.91 a 0.93)
Mucho mejor en encontrar TODA la información relevante. Las pistas contextuales ayudaron a descubrir contenido relacionado que los métodos tradicionales pasaban por alto.
¿Qué significan estos números en la práctica?
Estos no son solo indicadores abstractos: se traducen en beneficios reales y tangibles:
- Menos usuarios frustrados: una mejora del 34 %+ en la precisión del contexto significa que los usuarios encuentran lo que buscan con mucha más frecuencia.
- Mayor confianza: el aumento en fidelidad implica que los usuarios pueden confiar más en las respuestas.
- Mejor toma de decisiones: la mejora en la exactitud conlleva a obtener conocimientos más fiables a partir de los informes anuales.
- Menos verificación manual: una mayor precisión implica menos tiempo dedicado a comprobar las respuestas generadas por la IA.
Conclusión
El experimento con CUAC FM reveló varias ideas clave:
- El contexto importa más en consultas complejas: las preguntas simples y fácticas mostraron mejoras modestas, mientras que las consultas analíticas complejas mejoraron en más del 30 % en algunos casos.
- Complejidad de los documentos: los informes anuales contienen información interconectada donde el contexto es crucial—un campo de pruebas perfecto para la recuperación contextual.
- Beneficios compuestos: a medida que mejoraban los indicadores individuales, la experiencia del usuario mejoraba exponencialmente gracias al efecto multiplicador de una recuperación más precisa.
- Ganancias en consistencia: no solo mejoró el rendimiento promedio, sino que disminuyó la variabilidad—resultados más consistentes y fiables entre diferentes tipos de consultas.
La recuperación contextual representa un avance significativo en el diseño de sistemas RAG. Al preservar y aprovechar la información contextual durante todo el proceso de recuperación, podemos construir aplicaciones de IA más precisas, confiables y orientadas al usuario.
Las implementaciones en Python que se muestran aquí ofrecen una base sólida para incorporar recuperación contextual en tus propios proyectos. Comienza con una mejora básica del contexto, y gradualmente añade características más sofisticadas como contexto jerárquico y filtrado específico por dominio, según evolucionen tus necesidades.
Recuerda que la clave del éxito en la recuperación contextual está en entender tu caso de uso específico y adaptar la información contextual para alinearse con las necesidades de tus usuarios y los patrones de sus consultas. Con una implementación cuidadosa, la recuperación contextual puede transformar tu sistema RAG de una simple herramienta de búsqueda de información en un asistente inteligente y consciente del contexto.


