
Cómo arreglé mi cafetera usando un sistema RAG
- Fernando Souto
- Ai
- 4 de noviembre de 2024
Tabla de contenidos
Cuando mi cafetera decidió dejar de funcionar, revisar el manual fue simplemente doloroso y, honestamente, una pérdida de tiempo. Así que, en lugar de rendirme, probé algo diferente: utilicé un sistema de Recuperación-Aumentada por Generación (RAG) con un Modelo de Lenguaje Grande (LLM) para solucionarlo.
Comencé configurando un sistema de recuperación a partir del manual; esto me ayudó a organizar la información para que el LLM pudiera entender qué era qué. A partir de ahí, le hice al LLM algunas preguntas específicas. ¡Las respuestas fueron perfectas para solucionar problemas y me ahorraron mucho tiempo y frustración!
En resumen, logré que mi cafetera funcionara sin tener que adivinar. Esto demuestra cómo los sistemas RAG pueden hacer tu vida diaria más fácil. ¡Estoy emocionado de ver dónde más puede ayudar esta tecnología!
Puntos clave del PoC
— Base de conocimiento: Neo4j graph database
— Herramientas: Langchain QA chain
— Modelo: Azure OpenAI 4o
Como funciona
Paso 1: Instala las dependencias
Primero, carga todas las librerías en tu entorno:
pip install neo4j langchain-openai langchain langchain-community langchain-huggingface pandas tabulate
Paso 2: Inicializa tu base de datos Neo4j
Conecta con Neo4j inicializando la base de datos con tus credenciales. Verifica que las credenciales están seguras en unas variables de entorno.
from neo4j_graph import Neo4jGraph
enhanced_graph = Neo4jGraph(
url=os.environ["NEO4J_INSTANCE"],
username=os.environ["NEO4J_USER"],
password=os.environ["NEO4J_PASS"],
enhanced_schema=True
Paso 3: Inicializa el modelo de lenguaje
Ahora, configura el modelo de Azure OpaneAI usando tus credencialeS:
from azure_openai import AzureChatOpenAI
model = AzureChatOpenAI(
azure_deployment=os.environ['AZURE_OPENAI_DEPLOYMENT'],
model_version="2024-05-13",
api_version="2024-02-01",
temperature=0
)
Paso 4: Crea una Q&A con Neo4j
¡Aquí es donde ocurre la magia! Crearás una cadena de preguntas y respuestas configurando emdeddings, creando un vector store en Neo4j y configurando un retriever para obtener respuestas relevantes.
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_qa_chain import Neo4jVector, RetrievalQAWithSourcesChain
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
store = Neo4jVector.from_existing_index(
embeddings,
url=os.environ['NEO4J_INSTANCE'],
username=os.environ['NEO4J_USER'],
password=os.environ['NEO4J_PASS'],
index_name="vector",
keyword_index_name="text_index",
search_type="hybrid"
)
retriever = store.as_retriever()
sim_chain = RetrievalQAWithSourcesChain.from_chain_type(
model,
chain_type="stuff",
retriever=retriever,
verbose=False,
return_source_documents=True
)
Paso 5: Pregunta
¡Pongámoslo a prueba con una pregunta de ejemplo! Consulta el modelo y obtén resultados en segundos:
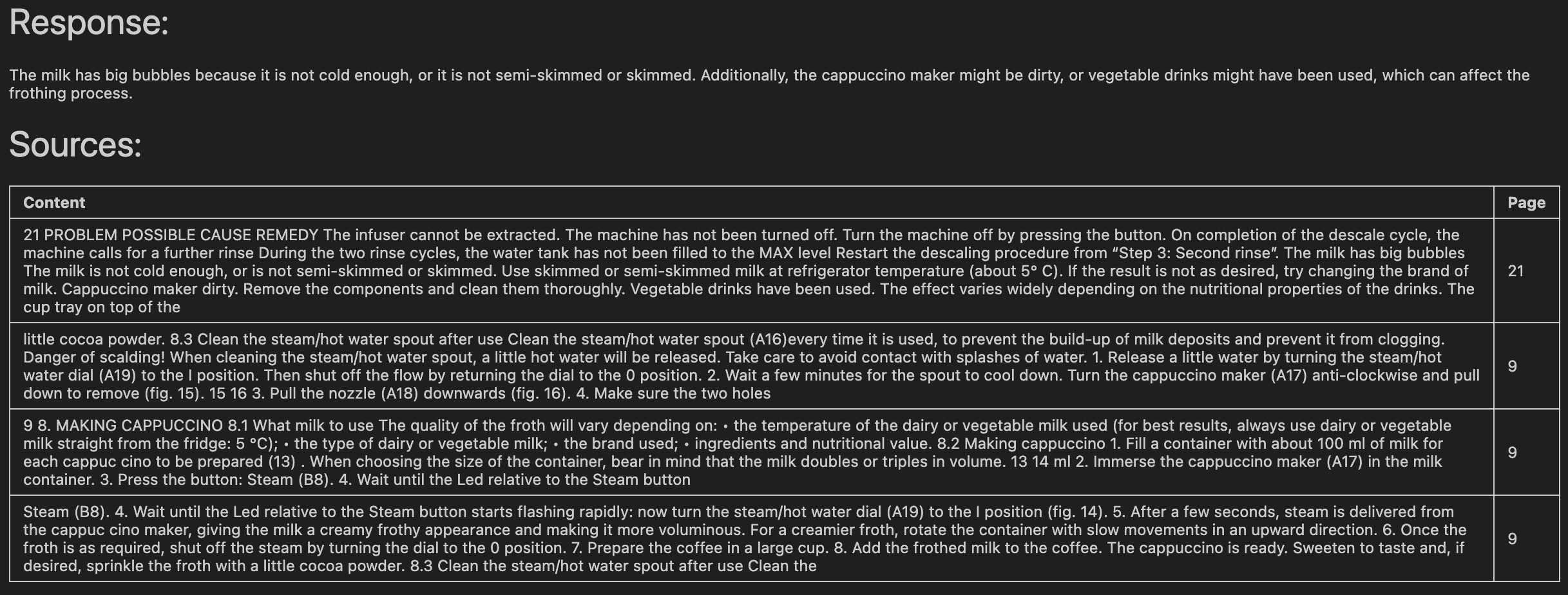
result = sim_chain("The milk has big bubbles")
Paso 6: Ponlo todo bonito en una tabla
Haz que tu output sea visualmente atractiva y organizada. Este truco de formato muestra la respuesta y las fuentes en una tabla bien estructurada con el contexto de la página:
import pandas as pd
import json
from tabulate import tabulate
from IPython.display import display, Markdown
data = json.dumps([{"page_content": doc.page_content, "metadata": doc.metadata} for doc in result["source_documents"]])
df = pd.json_normalize(json.loads(data))
df = df.drop(['metadata.position', 'metadata.content_offset', 'metadata.source', 'metadata.fileName', 'metadata.length'], axis=1)
df.rename(columns={'page_content': 'Content', 'metadata.page_number': 'Page'}, inplace=True)
display(Markdown('# Response:\n' + result["answer"]))
display(Markdown('# Sources:\n'))
display(Markdown(tabulate(df, headers='keys', tablefmt='github', showindex='never')))
Ya estaría!
Con esta configuración, ahora estás listo para hacer preguntas, obtener respuestas inteligentes de Neo4j y mostrarlas de manera atractiva. Esta integración no solo hace que tu base de conocimientos sea poderosa, sino también fácil de navegar e interactuar.


